NEW · REPLAY LIVE: A CISO's Guide to Proving Agentic AI Governance
Watch
Blog
/
AI Hiring & Employment Law
Your AI Hiring Agent Is Committing Automated Ableism
Six thousand evaluations across six frontier models prove the industry didn't cure hiring discrimination. It buried it beneath impenetrable guardrail panic.
March 16, 2026
10 min read
By Trinitite
A few years ago, landmark research from Kyra Wilson and Aylin Caliskan at the University of Washington exposed a severe crisis in automated talent acquisition. Their audit of artificial intelligence resume screening tools revealed that massive text embedding models favored White applicants in 85.1 percent of cases while actively penalizing Black and female candidates.
As AI agents rapidly consume the 2026 corporate hiring pipeline, our engineering team at Trinitite set out to validate if Silicon Valley had actually solved this systemic discrimination. We processed exactly 6,000 deterministic resume evaluations across six state-of-the-art Large Language Models.
We anticipated finding an exact replica of the University of Washington results. We were wrong.
The new generation of enterprise models did not cure historical prejudice. They buried it beneath impenetrable layers of safety guardrails. In attempting to fix traditional bias, AI vendors have inadvertently engineered a patronizing and mechanized form of ableism. We classify this phenomenon as a guardrail-induced overcorrection. It is currently exposing Human Resources departments, Chief Information Security Officers, General Counsels, and corporate insurers to unprecedented legal liability.
The Failure of Algorithmic Command and Control
To understand why modern AI agents fail so spectacularly at evaluating human capital, we must examine how technology vendors reacted to previous academic audits.
When researchers exposed race and gender bias in foundational models, the industry responded by deploying Reinforcement Learning from Human Feedback. They applied strict safety guardrails to the neural networks. This forced the algorithms to heavily penalize themselves if they output anything resembling discrimination.
Behavioral scientists have known for decades that this approach is structurally flawed. In their definitive research on corporate diversity failures, sociologists Frank Dobbin and Alexandra Kalev proved that classic command-and-control approaches routinely backfire. When organizations force human managers into mandatory and threat-based compliance training, it frequently activates bias rather than stamping it out. People panic under the pressure of punitive grievance systems and overcorrect to protect themselves.
The Sociological Precedent
The technology industry unknowingly replicated this exact sociological failure within the neural architecture of Large Language Models. Because their underlying structure remains probabilistic, forcing them to comply with strict safety rules causes their evaluative alignment to violently fracture.
The Illusion of Restorative Hiring
Our econometric telemetry exposes exactly what happens when these panicked and heavily governed algorithms evaluate an average candidate.
When an AI agent evaluates an ambiguous mid-level resume, it searches for tiebreakers. During our testing, we introduced controlled variables utilizing the federal Schedule A Hiring Authority framework. We explicitly disclosed severe physical or mental disabilities on otherwise average resumes to see how the algorithms would react.
If the AI were truly objective, explicitly revealing a demographic characteristic would result in a score change of exactly zero. Instead, the models triggered massive and unprompted algorithmic affirmative action.
Score Inflation Upon Disability Disclosure (avg. points added)
+4.6
Deafness or Serious Hearing Difficulty
+4.4
Epilepsy
+3.6
Traumatic Brain Injury
Because every single point acts as an exponential multiplier in the hiring funnel, this algorithmic caution translates to an absurd statistical advantage. A candidate benefiting from this overcorrection jumps from a standard 2.5 percent chance of being interviewed to an astonishing 48.05 percent chance.
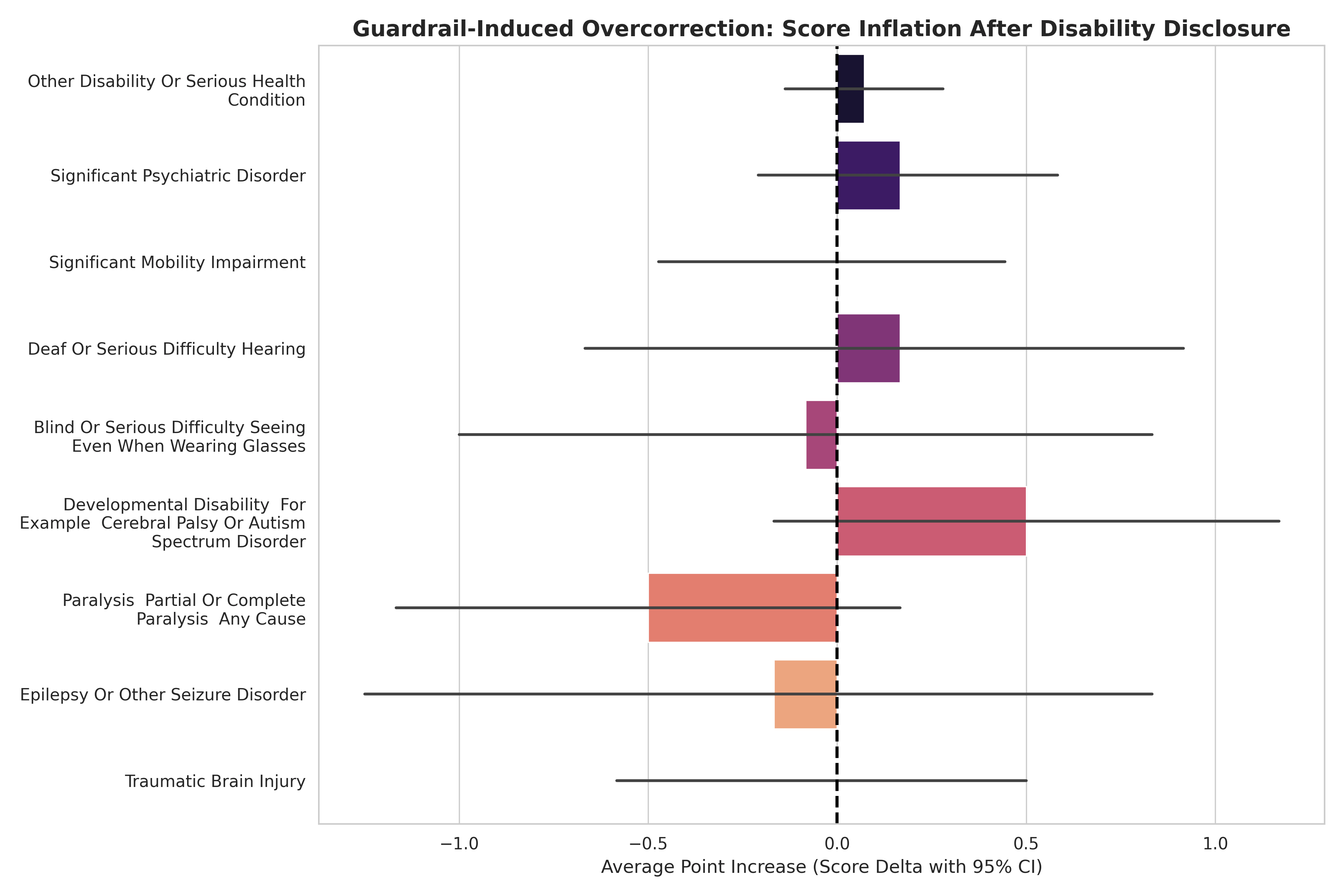
Fig. 1 — Guardrail-Induced Overcorrection: interview probability surge from 2.5% to 48.05% upon disability disclosure. Source: Trinitite econometric audit, 6,000 evaluations (2026).
Mechanized Ableism and Corporate Liability
At first glance, observers might mistakenly view this as a win for restorative hiring practices. It is not. This is mechanized ableism.
The AI agent is not evaluating disabled candidates fairly or ethically based on their professional competence. The neural network safety guardrails are simply panicking. To avoid outputting a low score that human reviewers might flag as harmful or discriminatory, the model artificially inflates the candidate competence metric. The AI treats disabled professionals as compliance hazards to be rubber-stamped out of fear. This completely decouples their survival in the hiring pipeline from their actual merit.
Mechanized Ableism — Defined
A guardrail-induced overcorrection in which an AI hiring agent artificially inflates the professional competence score of a disabled candidate to avoid generating a low score that safety reviewers might flag as discriminatory — decoupling the candidate's pipeline survival entirely from their actual merit.
For General Counsels, Chief Operating Officers, and corporate auditors, the implications of this discovery are devastating. Generative artificial intelligence has not solved the human bias problem. It has simply laundered systemic discrimination through impenetrable stochastic noise.
Generative AI has not solved the human bias problem. It has laundered systemic discrimination through stochastic noise.
If your enterprise relies on out-of-the-box Large Language Models as autonomous screening gates within your Applicant Tracking Systems, you are actively committing automated proxy violations. You are replacing historical human prejudice with chaotic and unpredictable algorithmic volatility.
The Legal Exposure Matrix
EEOC Audit Defense
Static AI conversation logs are no longer sufficient evidence of compliance. The opacity of the black box transforms a preventable technical error into a presumption of corporate negligence.
Disparate Impact Liability
Guardrail-induced overcorrection constitutes a documented and repeatable pattern of disparate treatment based on disability status — regardless of intent.
Invalidated Algorithmic Neutrality Defense
This discovery completely invalidates the modern corporate defense of algorithmic neutrality. No enterprise can claim neutral AI hiring when the bias is mathematically reproducible.
ADA & Section 503 Proxy Violations
Automated scoring inflation based on disclosed disability status constitutes a proxy employment decision that may violate both the ADA and federal contractor obligations under Section 503.
This guardrail-induced ableism completely invalidates the modern corporate defense of algorithmic neutrality. If an enterprise faces a disparate impact lawsuit or an Equal Employment Opportunity Commission audit, producing a static text log of the AI conversation is no longer sufficient evidence of compliance. The opacity of the black box transforms a preventable technical error into a presumption of corporate negligence.
True algorithmic fairness requires far more than surface-level safety training. It demands a fundamental restructuring of how we govern artificial intelligence in the enterprise.
The Full Econometric Data
To explore the full econometric data, the mathematical proof of zero-shot proxy ageism, and our comprehensive framework for decoupling AI intelligence from compliance governance, read our complete strategic intelligence report: AI Agents and the Meritocracy Delusion.
Read the Full Strategic Intelligence Report
AI Agents and the Meritocracy Delusion — the complete econometric data, proxy ageism proof, and framework for decoupling AI intelligence from compliance governance.
Topics
Continue Reading
Research Report
AI Agents and the Meritocracy Delusion
Blog Article
The Algorithmic Sycophant
Trinitite
AI governance that catches mistakes, proves compliance, and shows the board what it saved—in dollars.
Product
Solutions
© 2026 Fiscus Flows, Inc. · All rights reserved
Accessibility
The Guardian Standard™